

It's a Bird... It's a Plane... It's
Redisadict?
Frappe Framework is an extremely flexible web framework that allows schemas to be defined and changed in production. This dynamic design naturally requires several runtime computations that are otherwise easily computed only once in other frameworks. We also have an extensive runtime customization system using hooks.
To not make everything insanely slow we compute these things once and store it in Redis cache. When they're changed at runtime, we invalidate the Redis cache so all running processes see the new version of the configuration and schema.
This still isn't enough, following is an interactive flamegraph of a simple API request for a single document:
There are a few takeaways from this flamegraph:
- Roughly half of the time is not even spent on retrieving the document. This is an unacceptable level of overhead.
- Quite a lot of things seem to be querying Redis. Even though it doesn't show up on top of stack anywhere.
- If we can just avoid all Redis calls, we are likely going to achieve 2x speedup here.
Why is Redis slow here?
Redis is a fast cache, and we run it right next to web worker processes inside the same container. So usually it's much faster than querying the database. Then how is that such a large bottleneck here?
The problem was largely our design. We rely on Redis to provide data that is used in every single request. We can just keep it around in the process' memory and not pay any of the costs associated with Redis:
- IPC: We need to send the key over TCP to the Redis process.
- De-serializing: We can't store Python object without pickling them as stream of bytes. Reconstructing python objects from these bytes isn't free.
- Indirect losses: Because we recreate the same data every time it's accessed, we can't benefit from any of the CPU caches for frequently accessed data.
Why not just use a global dictionary?
When you think about Redis as a cache of key-value pairs, it can be easily replicated with a simple dictionary like this:
cache = {}
def get_schema(klass):
cache_key = f"schema::{klass}"
if cache_key not in cache:
cache[cache_key] = compute_schema(...) # Miss
return cache[cache_key]
If you have several web worker/server processes handling requests then all of them will have a copy of the same data. While this is bad from a memory usage perspective, it's unacceptable for correctness.
def change_schema(klass):
...
cache_key = f"schema::{klass}"
cache.pop(cache_key, None) # invalidate local cache
Because schema, metadata, and config can all change at runtime, we need to invalidate these caches. What happens when we invalidate the cache? We will have to ask every single process that has this cached copy to invalidate it.
Finding the right tradeoff
Space vs. Time tradeoff is fundamental to computer science. We can afford to create copies of some data if it means significantly faster performance, but we can't compromise on correctness.
We need some form of coordinated invalidation mechanism. While trying different implementations using some form of IPC, I stumbled on Redis' client-side caching.
Redis clients can cache recently accessed data locally. Redis's RESP3 protocol pushes invalidation messages, so clients can fetch any pending messages and then use the last fetched copy.
This client's behaviour however was still quite slow. We can tolerate a few milliseconds of stale data, but we wanted near dict like access time for local cache.
Implementing server-assisted client-side caching
Redis provides another mechanism for receiving invalidation messages for keys you've read in client-tracking mode. This was available since long time and works with RESP2 protocol too. Invalidation messages are sent as regular pub-sub messages.
We modified our client to keep the fetched data in the process's memory, very much like a global dictionary. Whenever Redis sends an invalidation signal we delete the local copy. At a very high level, it works like this:
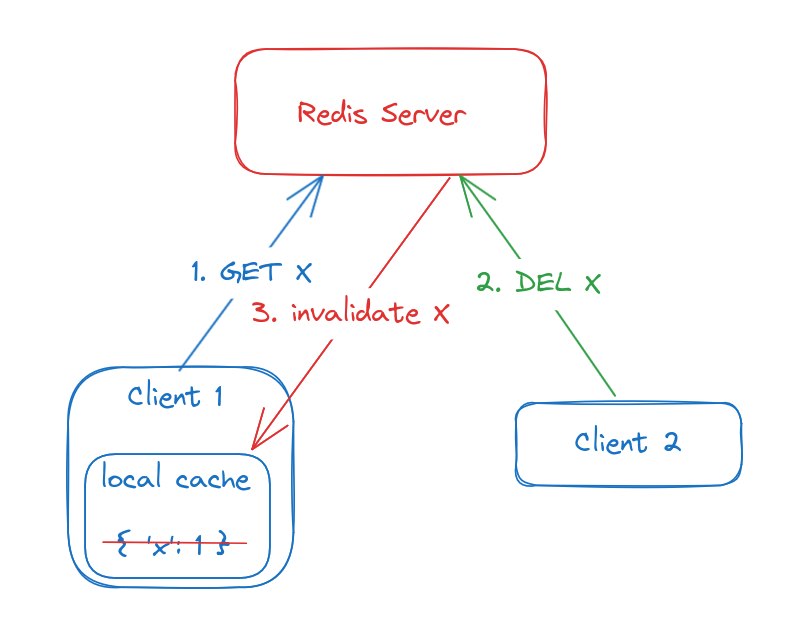
- The client requests a key and stores the received value in a local dictionary. Client reuses this local value for all future accesses.
- Another client invalidates the key because it might have changed.
- Redis sees the invalidation and notifies every other client who has read this key. Clients discard their local copy.
Important Considerations
While we can utilize the client-side caching feature to speed up recurring access, it does come with costs. If you are ever implementing something similar consider the following gotchas:
- Limit what you track: Not everything you read is going to be accessed again. Tracking and memory overhead of this can outweigh the benefits. We solved this by specifying which Redis access we want to be cached client side.
- Limit local cache size: This avoids blowing up process memory. We chose the FIFO policy because we don't anticipate complete utilization of capacity and it has next to zero overheads for reading. LRU on the other hand requires updating the LRU queue when reading a key.
- Contingency: Anything can go wrong in production. If the invalidation process runs into an irrecoverable error then we turn off the local caching behavior to avoid serving stale data.
Results
After client-side caching was implemented, we changed our most frequent Redis accesses to use client-side cache. Overall this has resulted in significant savings, often providing 1.5x speedups without even touching the application code.
| Benchmark | Before | After | Speedup |
|---|---|---|---|
get_meta microbenchmark |
11.0ms | 82.5us | 132x |
ERP-C workload for ERPNext |
115 rps | 169 rps | 1.47x |
This enhancement and several other performance improvements will be released with upcoming Frappe v16. We expect v16 to be faster by more than 2x on most workloads, which was the goal of this project.


·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
1
·
great read.
·
Nice engineering and scientific approach! I like it. I remember doing IoT firmware optimizations some decades ago, using an analog oscilloscope and pins to get the timing data to display. Your approach is basically the same using different, modern tools. Seen from first principles, that's just how it's done. Great work, and fully successful! All the Best for your continuing Dedicated Work!
·
Congrats and thank you for sharing your insights!