

In the beginning, we needed to move as fast as we could. Everything we built was just plumbed together. We took care of the happy path and left it at that. Frappe Cloud is now much further along its lifecycle. Now, we're trying to make Frappe Cloud a reliable infrastructure layer. So everybody can build stuff on top. It took some time to understand this. This is both an attitude problem and a skill problem.
About 6 months ago, the single biggest problem we had was uptime. It was becoming more and more difficult to keep putting out fires constantly. All this distracted us from making Frappe Cloud a better platform for Frappe Apps.
We finally decided to drop everything else and fix this problem.
Starting with All Hands
In October 2023, we started reviewing important metrics in the company-wide all-hands. Every team picks important quality metrics and tracks them weekly. The support team tracks SLA % and feedback ratings. We track uptime and incidents. Again, how you do it is not important, but that you do it. Any platform that can consistently drive change will work. All hands worked for us.
Almost all of the downtime was related to MariaDB issues. MariaDB would frequently freeze or restart. It takes MariaDB a few seconds to restart. But we run a lot of jobs on Frappe Cloud. The database restarting during these jobs is not just an inconvenience. It means we can get a broken site that cannot be recovered. That is much worse than minor downtime.
This affected servers with little memory, too many sites and too many SELECT queries. We would temporarily fix the problem by provisioning more memory, moving sites to other servers and provisioning more IOPS for EBS volumes. But throwing money and ops at the problem was not sustainable.
Failed attempts
One of the common triggers was logical backups. MariaDB logical backups are expensive. You are asking the DB to read all data from the disk. Data that you might never otherwise read. This is a lot of unnecessary work. However, completely disabling logical backups did not help much. Partial physical backups and restores are hard!
We collect a lot of metrics and logs about everything we run. Sometimes, these metrics are not enough. You need the exact event that triggered the situation. A query, request, file, process snapshot, etc. So, we started collecting as much data as we could think of. Like core dumps, stalks, and performance schema metrics.
Upgrading MariaDB sometimes helped. Once, it even backfired. MariaDB 10.6.16 would randomly stop responding to queries. MariaDB developers had already fixed this deadlock but did not release it. We had to build and deploy it on Frappe Cloud.
MariaDB memory usage
We eventually found a consistent symptom. MariaDB memory usage always monotonically increased (never decreased). MariaDB would constantly keep eating memory and never give it back. Eventually, it would hit the memory limit, then freeze or restart. It was going to happen everywhere eventually. Some servers had too much free memory for it to happen anytime soon.
We tried to postpone the eventual demise with artificial lower memory limits, lowering buffer pool size, etc. Lower memory limits prevented MariaDB from eating up all the memory. But MariaDB would frequently hit this limit and restart.
Solution
One thing kept popping up on docs, issues, and random blogs, using a different allocator. In Python, we do not need to worry about where our objects reside and how they're laid out in memory. But somewhere down the stack, someone has to. Allocators handle this low-level detail.
The solution. One line config to get MariaDB to use a different allocator.
It worked well! Restarts dropped from 100 a week to 10. This was an anti-climactic but satisfying win. This was the biggest MariaDB problem I have seen. It is also the biggest improvement with the smallest change.
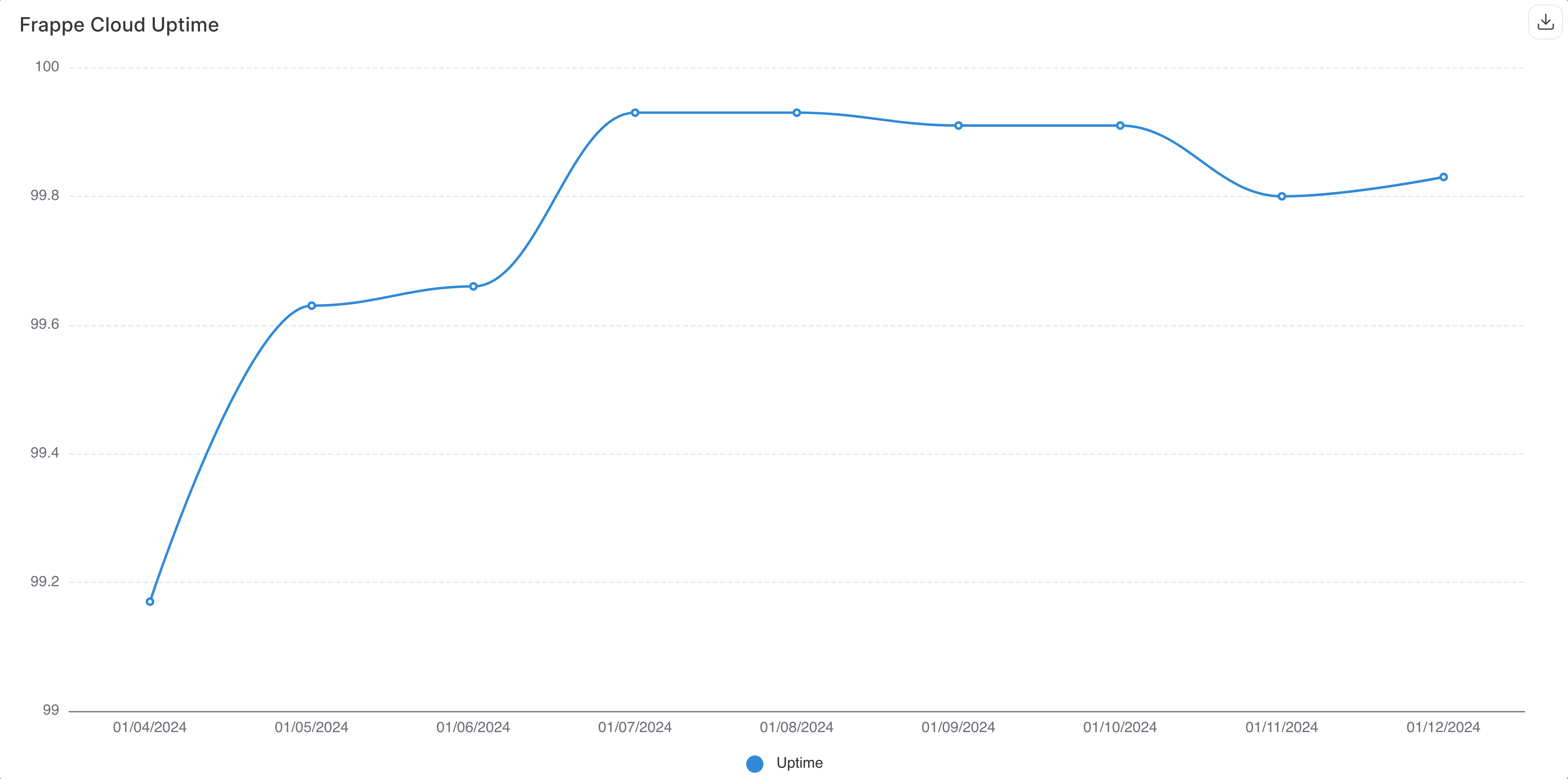
Uptime improved after using TCMalloc instead of GNU Malloc
Running out of disk space
One of the other sources of downtime was running out of disk space. There were some specific triggers.
- Framework decompressing backups on disk before restoring
- App-level issues causing too many writes and flooding MariaDB binary logs.
- Large sites migrating to Frappe Cloud
Sometimes, this was out of our control, so we built the automation to increase disk space.
This brought us another problem: disks with unused space. AWS does not let you reduce the size of an EBS volume. We eventually fixed that.
Debugging stories like these are fun. But the actual work is almost always a lot of pain. Getting a call in the middle of the day is a minor distraction at best. Getting one at midnight is pretty annoying. I can laugh at my naivete and stupidity now. But this has been one of the most traumatic events in my career so far.


·
Eye opening. Rooting for FC.
·
very informative
·
That was a very interesting, transparent and well received glance at an aspect of the reality of operations and at the team's effort to build a better sustainable infrastructure. Yes, stuff happens. And we can learn from it and adjust attitudes, as you also describe very well, which offers it as a lesson and material for reflection to everyone. Thank you, Aditya!