


Preface
We have been recently working on bringing auto-scaling to Frappe Cloud and are almost ready to make it public. 4 of Frappe Cloud's public servers are now using auto-scaling including frappe.io production server.
On 12th January, 2026, Frappe Cloud faced an almost 5-hour outage on one of our public servers in the Australia region. This blog post is an RCA of the incident while also explaining how the Frappe Cloud team tackles such incidents.
Below is a table of events and timestamps from when we identified the issues
| Event | Timestamp |
|---|---|
Low Memory Incident Alert on f1-sydney |
13:05 |
| Unnecessary auto-scale triggered | 14:40 |
| Sites Down | 16:50 |
| We found all the data and started recovery | 20:12 |
| Recovery completed and Sites were Up | 21:20 |
Investigating the Incident
2 months ago, when auto-scaling was still in its infancy we had set it up on f1-sydney. Primarily, because it was the newest cluster with very little traffic and fewer sites on it. It was an ideal target to test auto-scaling. Also, the way auto-scaling is done now is a bit different from how it was done 2 months ago, and it wasn't setup with new processes on the Sydney server.
The problem did not really start from a click on the server dashboard but from an out-of-memory issue on the App Server. To what the Analytics charts say, f1-sydney was facing low memory issues from approximately one day before this incident happened. Whenever there is an incident happening the Frappe Cloud team gets SMS and phone calls regardless of what time it is. But, we receive a call only when either of Site, DB or the App server are down. There was nothing down on the day before that, so the incident investigator didn't bother us. But, on 12th January, 2026, we received our first notification that the Database on f1-sydney was down. We tried rebooting the server but that did not really help. The server was also at its maximum resource utilization. Now, you might wonder if it had auto-scaling enabled, why did it not auto-scale already? It should've happened but it did not happen because it needed to be scheduled.
The same day was also the Version 16 release date. We had very few people in FC to work on any such abrupt incident. Most of the engineers were busy setting up prerequisites on the Frappe Cloud side for version 16. It was around 4 PM when Version 16 was almost going to go public, people were creating releases and tags with "version-16" and that is when we started getting calls from f1-sydney. All the 130+ sites on f1-sydney were down.
The effect on the customer sites was "site-url 404 not found". One of our engineers quickly started investigating what was wrong and why all the sites returned 404 altogether. 1 hour had passed, and our engineer who was looking into the incident still couldn't find the root cause. By now, we had started getting tickets regarding this, but the debugging was still going on with near to nothing useful.
Four of us got on a call and we started discussing about what all actions were performed before and after the incident. We never really have time to discuss this because the first priority is always to get the sites up as soon as possible. But the discussion always continues while one engineer is sharing their screen. During the discussion, we got to know that auto-scale was triggered on the sydney server and auto-scaling setup on that server wasn't up-to date. This also means that the setup was near to broken and an auto-scale shouldn't have been triggered. But lack of knowledge had led one of our engineers to trigger an auto-scale on it. The scale-up triggered on the server failed. So, to disable auto-scaling on that server there was a tear-down performed on the secondary server. Both jobs had failed mid-way.
In short, we achieve zero down time by using the secondary server and routing everything to the secondary server while the scaling is complete on the primary server. Once, the scaling is completed, we revert the traffic and processes to the primary, and the secondary server stays behind waiting for its next scaling opportunity. Currently, auto-scaling is available both automatically and on a scheduled basis. It can be configured to trigger automatically as well as can be scheduled to happen at a particular time in day.
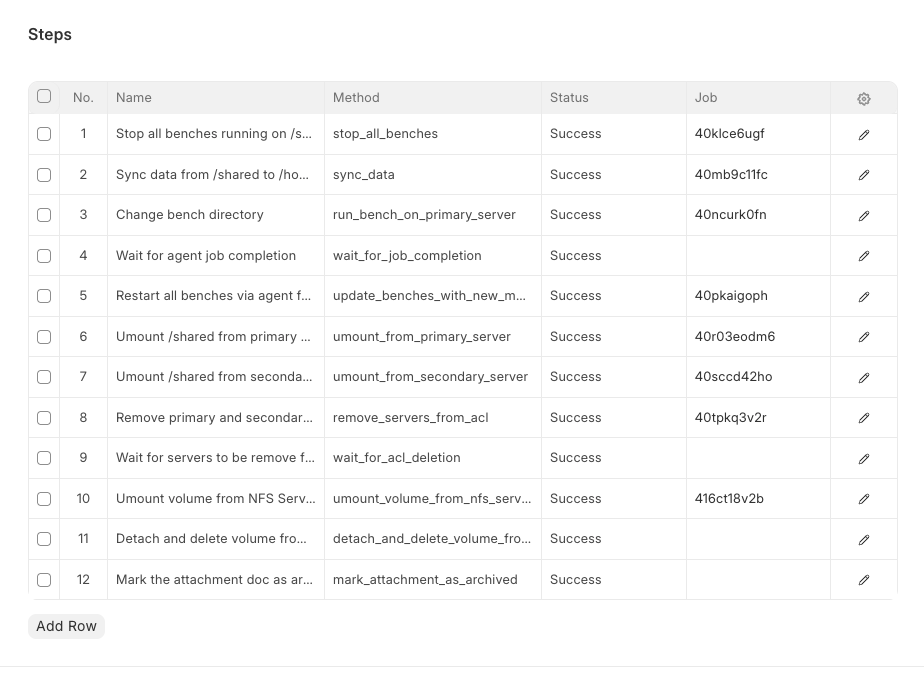
By now, the information we had was that all the sites were down, because their benches were missing from the server. On Frappe Cloud, every site is installed on a bench, and that bench is basically a docker container. All the sites run inside that docker container.
Where did the benches go?
While the sites were dead, agent was still running on our production server and was trying to do its day to day job of taking backups, updating sites whenever triggered by the customer and etc. But, all the sites were down and agent kept on returning the status "Undelivered". This made complete sense. We kept digging further into the details of the agent jobs.
We checked for the data in the volumes attached on the primary and secondary server. We prepared a list of missing benches on f1-sydney and started finding the rest of the benches. On Frappe Cloud, behind the scenes, all the add on disks bought from the cloud providers are mounted as /opt/volumes/benches/. We checked them on both servers, but we couldn't find the missing benches in either of the volumes.
One engineer suspected that since things broke down in between it could be probably that there was a sync happening between the directories on the primary and secondary server. And this was correct.
Remember the secondary server tear-down that failed mid-way? That mid-way was when the benches had started moving to a common parking space for all the benches called /home/frappe/shared. This directory is a common volume which is mounted across the primary, secondary and the NFS server. The copying of benches to /home/frappe/shared was interrupted. That is why only a few benches were on the primary and the rest of the benches were on /home/frappe/shared. At this point, there was a sigh of relief. We had found all the benches and there was no sign of any data loss.
The job steps from the scale-up were clear evidence to that hunch.
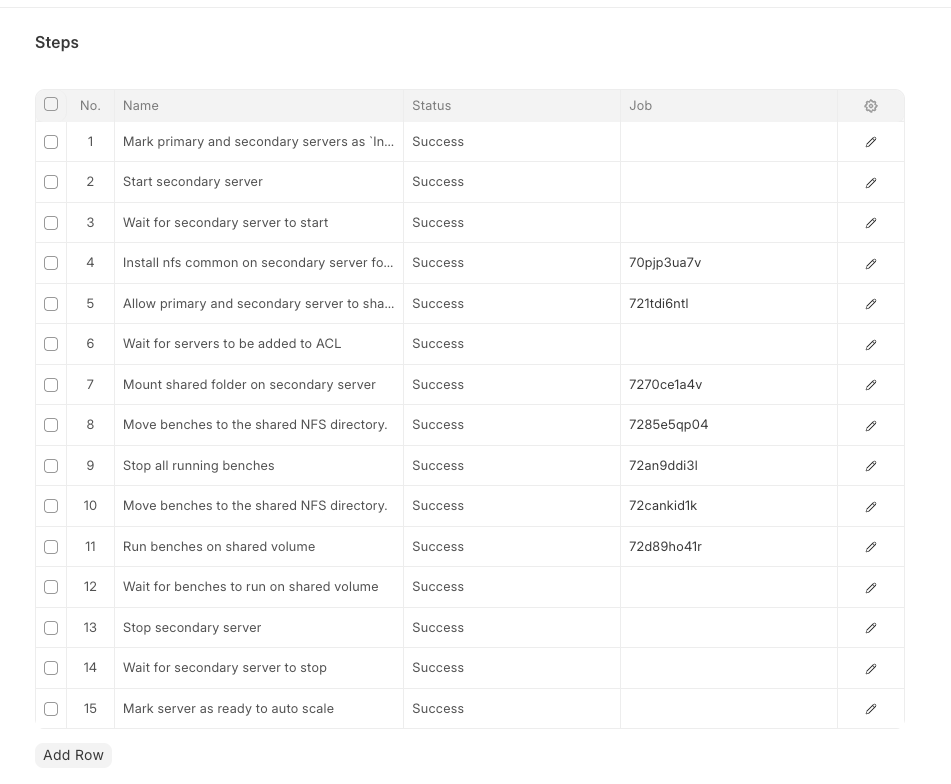
Recovering
Ideally, the /home/frappe/shared directory was made so that once the server scales up, that directory would serve as the primary base from where the containers would start. You can also see in the above image that there is syncing happening between both the directories (/home/frappe/shared and /home/frappe/benches). By default, on a server without auto-scaling all the containers run from the /home/frappe/benches directory.
Things after this were pretty straightforward, we had to make sure to move all the benches on their desired locations, restart the benches and the sites should be functioning normally.
cd /home/frappe/shared
mv ./* /opt/volumes/benches/home/frappe/benches/ -v
Once the copying was done, we restarted all the containers. That took quite some time. We had to restart 38 containers on that server and it took around 40 minutes.
After almost 5 hours, all the sites were now up but with broken CSS and missing icons. The data was completely untouched, but the assets for all the sites were broken. This was the final step—we manually rebuilt all the assets for the sites and everything was good to go. Rebuilding all the assets took another 1-2 hours.
Human error is sometimes undeniable
This incident was purely due to poor communication and lack of clean-up.
With every incident our team learns a lot of harsh lessons. The frequency of incidents happening on our server has seen a gradual decrease over time.


·
Glad everything worked out at the end These incidents are all a part of life Keep up the great work
·
Learning comes with humiliation!