


All the apps built on Frappe Framework have a lot of background running jobs which are responsible for doing certain tasks which needn't have to run on the foreground of the system or app. A lot of times the Job Queue (redis) gets flooded with a lot of jobs. There are always multiple reasons for the queue to grow longer and it might not always end up getting cleared.
So, from quite some time in Frappe Cloud we’ve been facing this situation related to rq workers going orphan at any random moment. And because this happens on our cloud.frappe.io production server we are all alarmed and on our toes. The App servers are now filled with jobs in "Pending" states and are not able to process site update, backups and all the other jobs.
Last week, a similar issue started occuring when 3 of our App Servers (2 in Singapore and 1 in Virginia) were having a lot of jobs pending from 8-12 hours. We woke up to incident calls and started looking into this issue. In engineering, you always prepare for the worst case but always start by doing the bare minimum. So, we did the same we went ahead and started cancelling long running jobs but that did not help us much as things weren't really working. The problem was way more than just jobs being pending.
We quickly remote logged into our server and ran htop to monitor running jobs on the server machine. It turns out there were around 20+ processes on PID 1 which meant they were orphan processes. These processes included Agent Jobs, Gunicorn workers (majority of those) and a few socket-io processes. To get everything back to normal, we quickly SIGKILL'ed all of them and then all the three servers were back into their jobs and started processing user requests properly without hanging up on the noose. The bare minimum to get situation in control was done.
Now, the actual fun part begins when started digging deeper into why the jobs kept on becoming orphan. We opened /var/log/syslog and started going through it line by line and monitor logs on day basis. The timestamp we referred was equivalent to when the jobs started getting stuck into pending states (it was either 07:00 AM or 19:00 PM), that is also when cloud.frappe.io server starts taking its backup. The backup is taken at minute 0 past every 6th hour (0 */6 * * *), assuming it takes an hour to complete. This delay causes a lot of jobs to queue behind each other eventually leading to heavy memory consumption.
On the production backup like all of your customer sites we also exclude a few core doctypes responsible for storing logs as not everything they have is always 60-90% useful. We decided to add a few more doctypes to be excluded from being backed up to reduce backup duration. After that our list looks something like this.
"backup": {
"excludes": [
"Agent Job",
"Agent Job Step",
"MariaDB Stalk Diagnostic",
"Deploy Candidate Build",
"Deploy Candidate Build Step", # New Addition
"Alertmanager Webhook Log", # New Addition
"Site Job Log",
"Site Request Log",
"Server Status",
"Site Uptime Log",
"GitHub Wehook Log",
"Error Log",
"Scheduled Job Log",
"Version",
"Email Queue"
]
}
We then started digging deeper into the logs after excluding a few more backups. The series of processes getting killed was also rather expected and obvious to Ankush. It all started with the production backup taking too long. After that it was time for Redis Server to be a little attention hungry and kill itself. Then there was no way rq jobs were going to survive on their own. Eventually, leading to the suicidal maniac of this theatrical drama of systems.
It was hard to wrap our heads around what RQ Job were taking 48G - 53G of the total server memory. So, even now we don’t know what RQ job or process is causing so much memory. We surely have a list of suspicious jobs our team has written in the past and we plan to refactor them sooner.
The bottlenecks here were long running jobs and those long running jobs consuming memory. So, we thought why not just limit wait time for child processes which are being supervised ? We allow 360s of duration for supervisor to wait for a process to complete. Here, supervisor is a dumb piggy waiting for the processes to complete for around 5 minutes which surely is troublesome. Though, supervisor here has 0 idea that the rq jobs might take longer than 5 minutes to complete. Hence, we thought we’d reduce supervisors wait time to 20s. But, after discussing with each other we thought this wasn't really going to help and we ended up dumping this idea. Maybe, we'll explore this once again in the future when we have more and more servers with a lot of jobs running on them.
The output of the command sudo systemctl status supervisor is like the below on normal days when everything is chill. But the day we were debugging, the memory consumption lied between 48 G - 53 G out of 64 GB memory. This consumption was just because of supervisor alone.
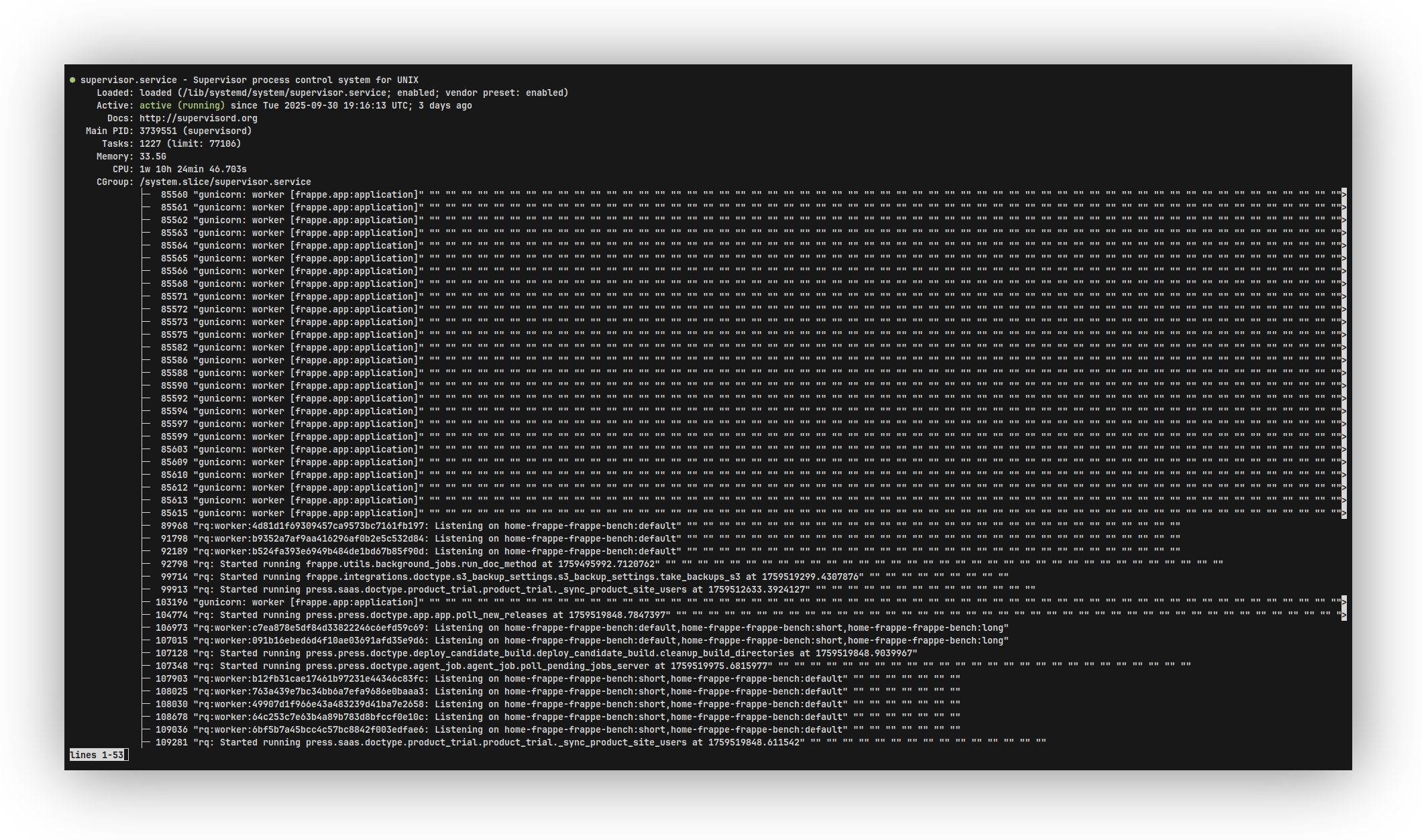
While going through the logs we noticed multiple instances of oom-killer and then these line beacuse of which all the trouble was being caused.
Sep 27 19:13:48 app supervisord[2763373]: 2025-09-27 19:13:48,368 INFO waiting for frappe-bench-frappe-build-worker, frappe-bench-frappe-sync-worker, frappe-bench-redis-cache, frappe-bench-redis-queue, frappe-bench-node-socketio...
Sep 27 19:13:48 app supervisorctl[3211063]: Shut down
To see more details of the supervisor service, we ran sudo systemctl show supervisor to see the options defined in the systemd service and searched for 'OOM' in it. We found this below line in the output which said,
NRestarts=5
OOMPolicy=stop <- the trouble maker line
ExecMainStartTimestamp=Tue 2025-09-30 19:16:13 UTC

To explain in the most simplest manner, this policy is a direct instruction to systemd if any of child processes under supervisor is oom-killed, systemd has to go and kill supervisor itself. This is why we saw supervisor shutting down in the logs. It was a huge surprise when we got to know about this.
Well by now, oom-kill enters the game and starts the killing. That is when this OOMPolicy=stop policy comes into a wilder mode. This stop policy just kills the whole service if any underlying process is killed. The actual drama on our production starts because of this, the supervisor of all service is now dead and killed because of the OOM, all the jobs now get their admissions in the orphanage. This leads to all the random issues we have to deal with on FC Production.
Protecting the piggy
We adjusted oom-score to -1500 in /lib/systemd/system/supervisor.service.
OOMScoreAdjust=-1500 # protects from oom-kill
Most importantly, we changed the OOMPolicy to not kill supervisor.
OOMPolicy=continue # let the process die, but don't kill the god father
We did all of these changes on October 1, 2025 and since then at least we haven’t faced the same issue again. it's fun how in software even the supervisor needs a supervisor to protect itself from OOM.
Reference
This post Supervisor Orphaned Processes was a great help to our engineers the first time they faced this issue related to orphan workers.


·
Very well explained Mangesh!