

The Frappe Cloud team started 2025 with a long list of known problems and one ambitious project. As the year unfolded, we achieved some of our goals but also diverged from others as new challenges came our way from customers or through our own problem discovery. Eventually, 2025 turned out to be a year of many small, deliberate improvements and not one of big launches. Frappe Cloud is Frappe’s heart, and here is an attempt to chart out its beats through the year 2025. It’s a recount of major developments, a celebration of milestones and also a reflection on what we could achieve or not achieve. Stay tuned…
Table of Contents
- Foundational improvements in infrastructure
- Improved visibility of storage and data
- Improving resilience
- Solving challenges of scale
- Growing up as a business platform
- Becoming more efficient and quality-focused
- Growth across all dimensions
- Looking back at 2025 and ahead at 2026
Foundational improvements in infrastructure
ARM migrations
This project came from a simple observation. When Aradhya rejoined Frappe after his master’s degree, he noticed that all the application servers in Frappe Cloud were running on older Intel machines, even though ARM-based servers would have been economic and more efficient. Aditya had already migrated the database servers earlier. Aradhya, raring to contribute after a year of being away, immediately picked up the project of ARM migrations and completed it within a couple of months. The impact was immediate and tangible. We reduced compute costs by half, and moved to a newer generation of machines and a much cleaner storage model (viz., our user data now lives on EBS instead of root disks, which eliminated a whole bunch of “disk full, nothing works” incidents.)

Registry refactor
Frappe Cloud’s Build servers are on DigitalOcean. DigitalOcean has a limit on disk space, and it is also expensive. As a result, we had to clean up the disk regularly by removing old images. But that led to an issue - when the App Server tried to pull an old image, it would often be non-existent. The result? The deployment would fail. Aradhya fixed this by refactoring the registry layer, moving storage to S3 (which is bottomless) and introducing regional mirrors so that images remained available. As a result, deployment failures reduced from ~9% to ~1.5% on average (6X improvement).
Improved visibility of storage and data
Application Server Storage Breakdown
As Aradhya delved deeper, he realised users were confused about how their storage was being utilised. A common question users asked was, “I paid for X GBs, but why do I see only Y GBs available?” Well, they had an option of SSH-ing into servers and manually inspecting directories, but that wasn’t elegant. So, Aradhya built Application Server Storage Breakdown**.** It gave users clear visibility into how benches and other components consume space, removing guesswork and command-line effort. (Read more)
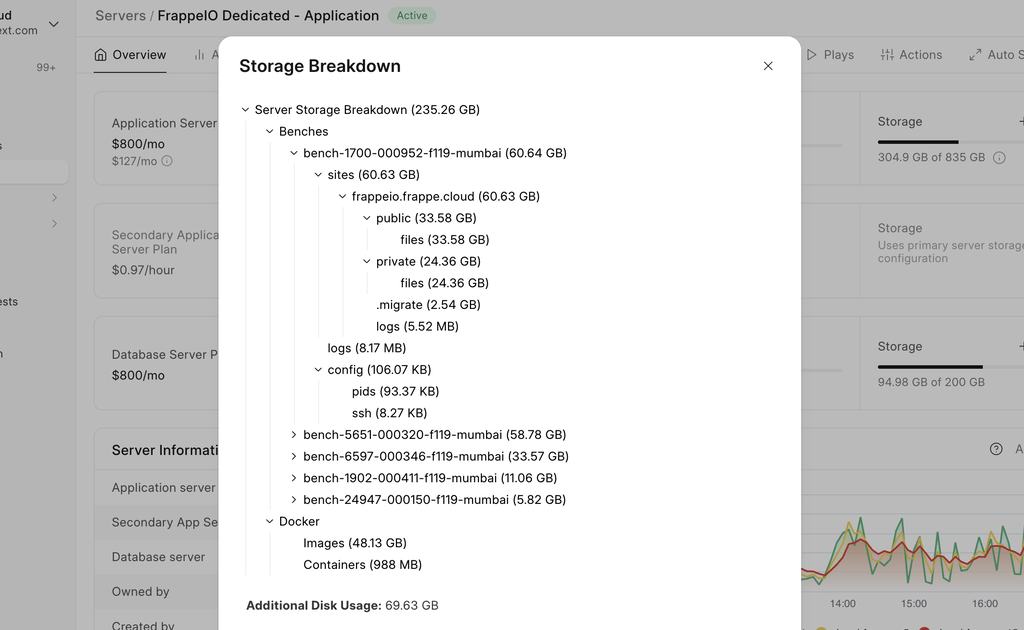
Database Server Storage Breakdown
A similar issue also came up on the database side. Customers, especially those moving from Shared servers to Dedicated servers, would often complain of storage getting full and the server going down. Interestingly, their site-wise storage wouldn’t add up to the total storage in the plan. That led to quite some confusion and, naturally, a lot of support tickets. As it would turn out, in most cases, the culprit was binlogs (the quiet but demanding recorder of every change in the database). Binlogs would often exhaust the disk space over time, sometimes even consuming space of the order of actual site data. While binlogs were not a foreign concept for developers, the issue was again the ease of investigation. Tanmoy (our de facto owner of everything database) built a Database Server Storage Breakdown feature, which brought all citizens of the disk space into light. (Read more)
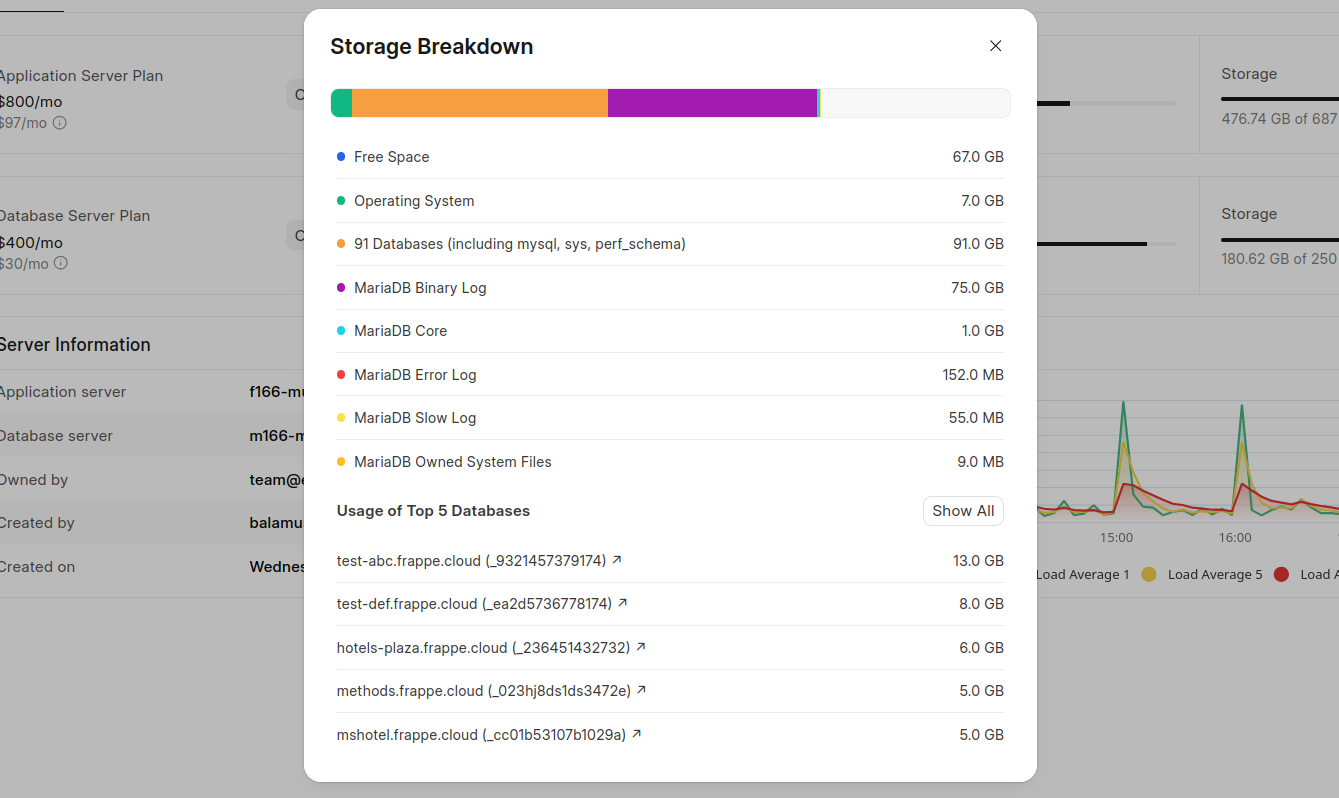

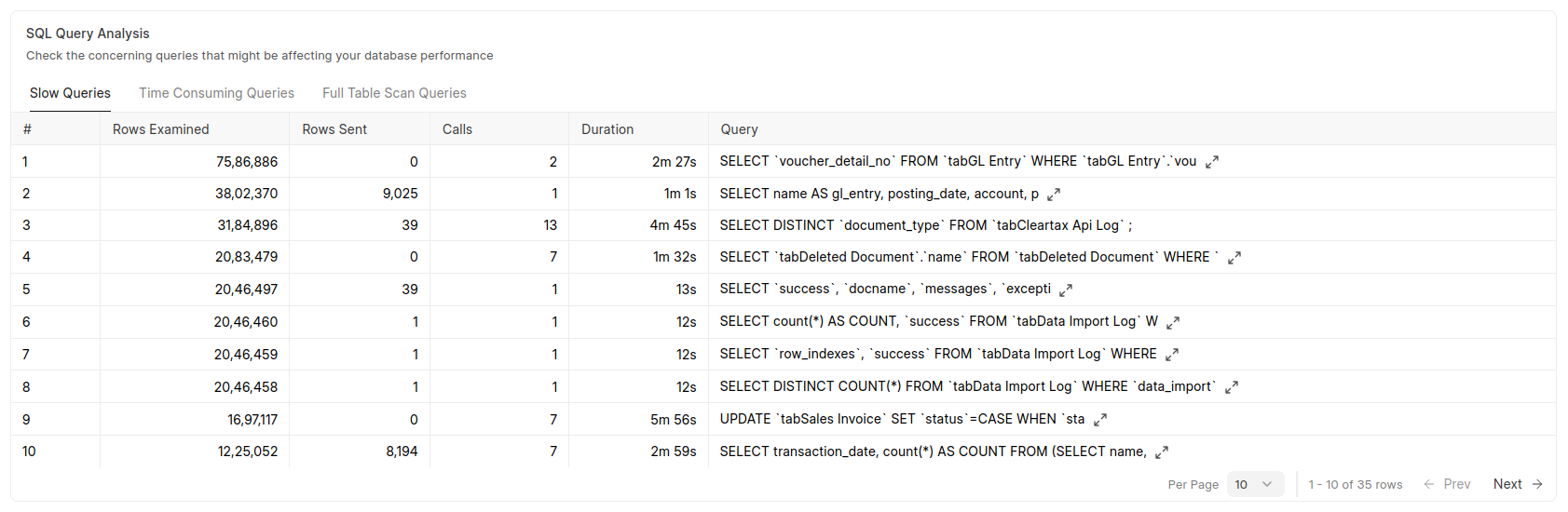
Database Analyzer
Over time, Tanmoy realised that a lot of performance issues on Frappe Cloud weren’t infra issues at all, but database behaviour issues hiding in plain sight. We had a SQL playground to assist, but it still required the user to already know what to look for and do a lot of detective work with logs. Database Analyzer made that work far more systematic by showing storage breakdown, process analysis, query analysis, and index analysis in one place. The tool now complements charts in the Insights tab and other dev tools, making troubleshooting much easier for customers and Frappe support teams. (Read more)
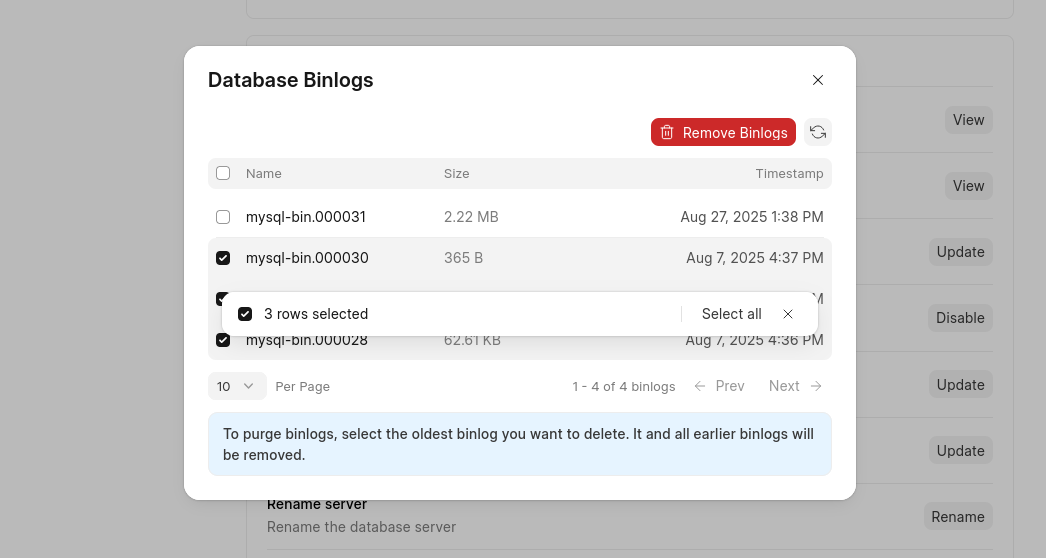
Binlogs management
As the saying goes, the reward of good work is more work! I think Tanmoy would agree more than anyone. Once users could see the disk utilisation, tickets shifted from “why is my disk full?” to “can you clean my binlogs?”. Users don’t have direct server access, and knowing the issue naturally made them demand a resolution for those who had access. That gave Tanmoy his next logical project. He built a utility that allowed users to safely view and purge binlogs themselves from the dashboard.
But binlog spikes are like Chernobyl before the explosion. Everything looks normal on the surface, but pressure is quietly building inside the system. A small misconfiguration or bad workload keeps adding heat, unseen and unchecked. By the time something breaks, it’s already too late. For customers, especially those who turned off the storage add-on to control costs, when binlogs spiked, their database became unusable before anyone could react. So, Tanmoy built another feature - auto-purging binlogs. This feature closed the gap by allowing users to define safe limits so the system protects itself before things spiral into downtime. (Read more)
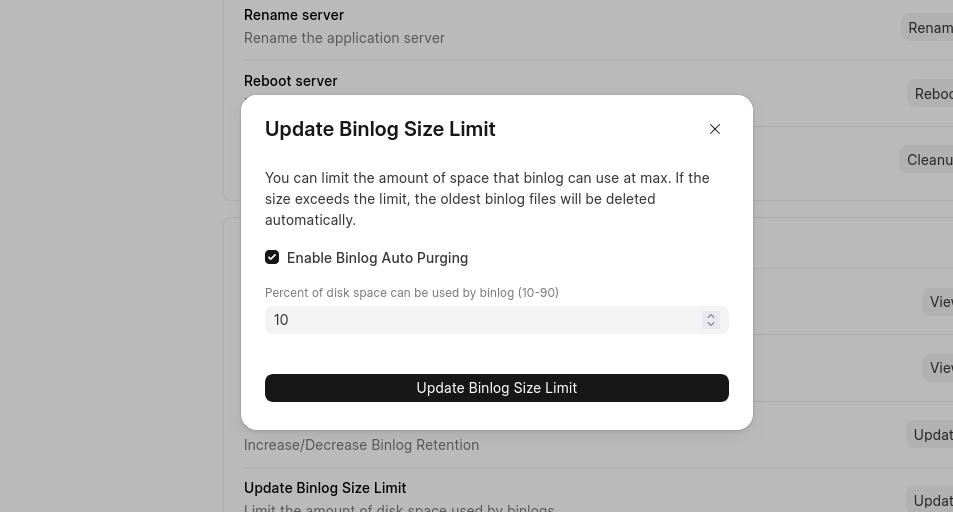
Binlog browser
While the database server storage breakdown and binlog utilities were enough for most basic investigations, we often got tickets where “someone deleted something”, and users wanted point-in-time recovery. These tickets came to us because on the user side, the developers only had some CLI tools (to find the timestamps inside binlogs), which were not very friendly to use. So Tanmoy took on the challenge and built a Binlog Browser that transformed raw, developer-only metadata scavenging workflows into an intuitive interface where teams could inspect database changes, investigate accidental deletions, and even diagnose bad customisations (redundant writing on servers, storing images on database, etc). As a result, what earlier used to require deep database expertise became far more approachable for user teams and Frappe support alike. (Read more)
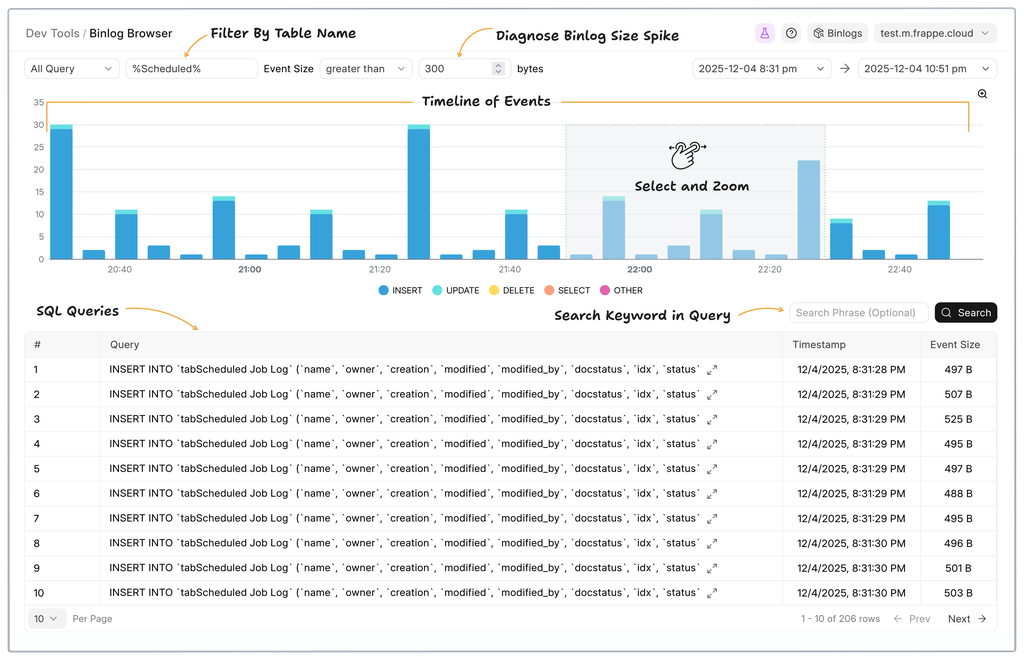
New charts
Balamurali (the backbone of Frappe Cloud L2 support) also added a few new charts to the Insights tab on the Frappe Cloud console. For e.g. the “Background Report Duration” chart to identify which background reports are taking the most time to generate, and the “Run Doc Method Duration” chart to help users see which specific methods are slow (if they are using runDocMethod in their custom app).

Improving resilience
Physical backups
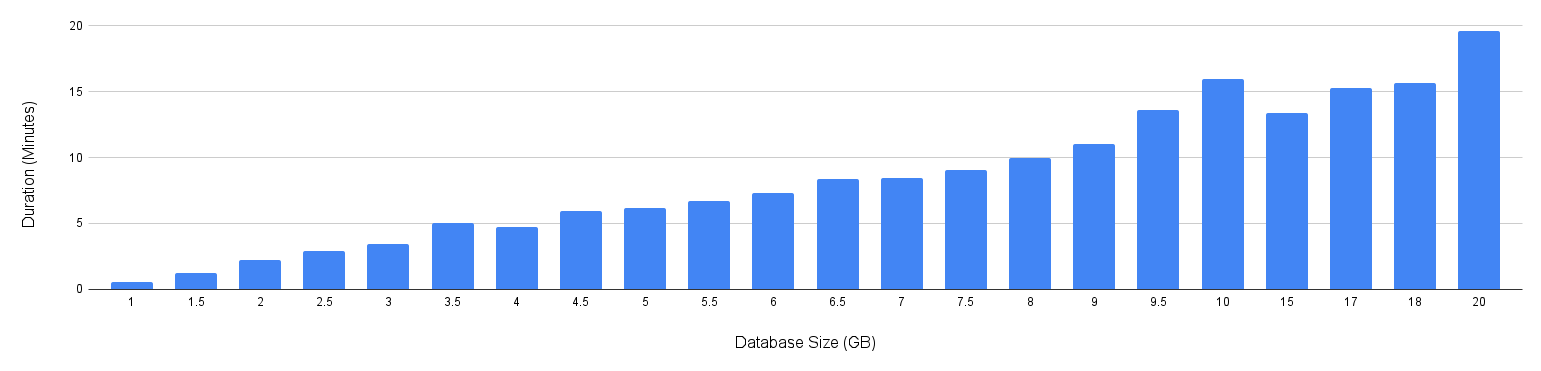
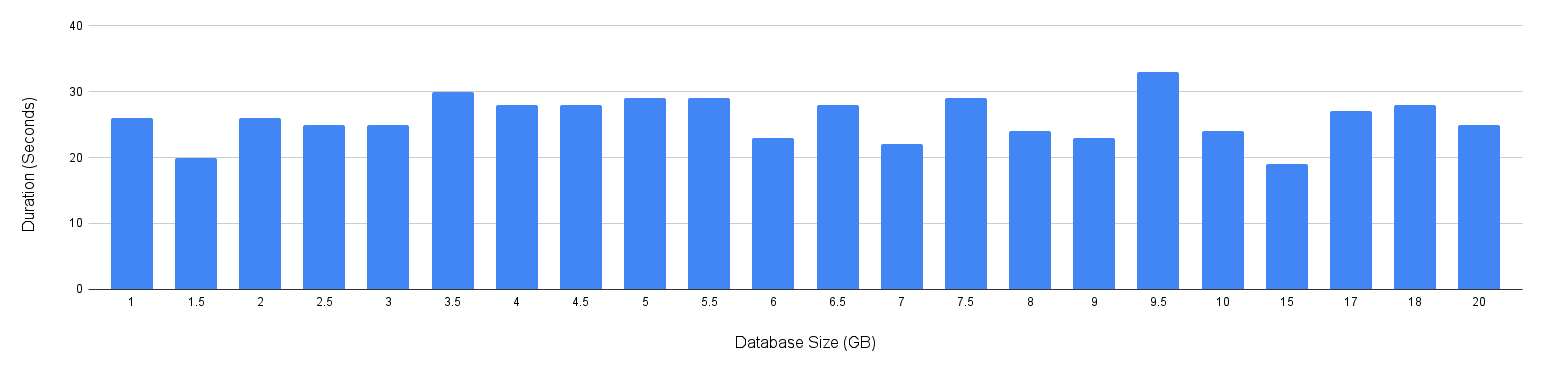
Visibility and transparency just solve half the problem. The rest is - Recovery. As databases grew larger, our existing backup approach started showing its limits. Logical backups scaled linearly with database size, leading to higher cost and time taken. As Frappe Cloud triggers automatic backups before initiating upgrades, long waits became inevitable when starting an update, disk I/O used to often max out, and performance impact became noticeable. Tanmoy then came up with the idea of Physical backups, and that changed the equation. By combining database locks, disk snapshots, and engine-specific restoration techniques, we were able to take backups in seconds instead of minutes, regardless of database size. (Read more)
Here is how backup duration changes with the size of the database for logical backups - linear increase.
And, here is how the same chart looks for physical backups - remains flat.
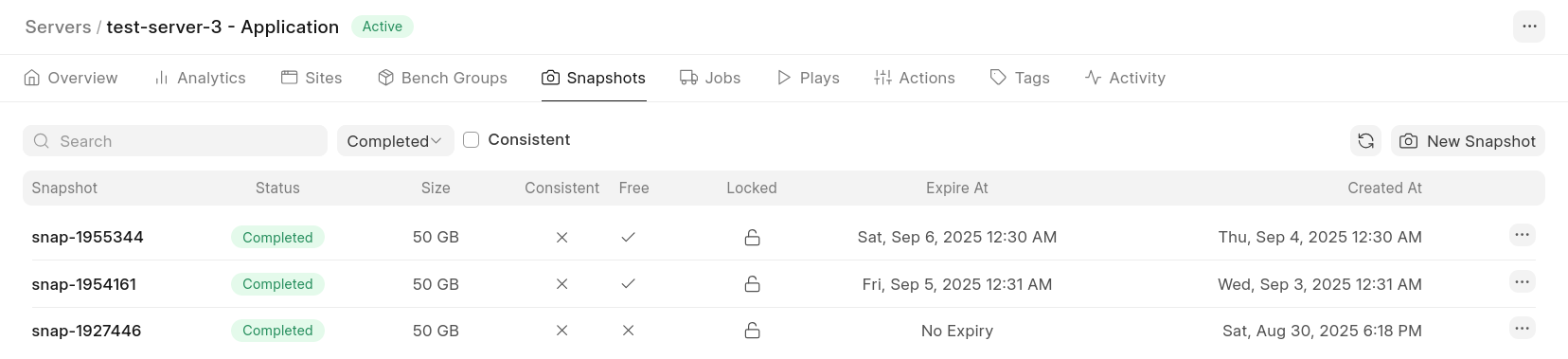
Server Snapshot Management
Backups are comforting only when users can actually see them, control them, and use them without opening a ticket. We already had server snapshots running every 24 hours, but customers couldn’t view them, couldn’t take one on demand before a risky change, and couldn’t recover everything on the server themselves when something went wrong. Server Snapshot Management (again built by Tanmoy) changed that by making snapshots visible and user-controlled, allowing manual snapshots, longer retention, and self-serve site recovery from a chosen snapshot. It also ended up simplifying disaster recovery and database replica provisioning. (Read more)
Restoration CLI
With better backups came the need for better restoration workflows. Upload limits on the dashboard made large migrations painful, especially for self-hosted customers moving to Frappe Cloud. The Restoration CLI addressed this issue by providing a simple, intuitive, and cross-platform (Windows and Linux) tool that could reliably upload, restore, and track large datasets. (Read more)
Solving challenges of scale
Autoscaling
When Aradhya presented ARM migrations and Server Storage Breakdown at Frappeverse 2025, he started getting questions on the next level of performance - Scalability. Until then, Frappe Cloud allowed manual compute addition, but when workloads spiked unpredictably, Frappe Cloud had no answers. Auto-scaling changed that (although still in beta). By allowing a site to move dynamically between a primary and a secondary server, Frappe Cloud can now respond to unpredictable load without downtime. Capacity is added when needed, workloads move safely, and everything scales back down automatically once things stabilise. (Read more)
Notification channel refactoring
Users always like to be informed about specific events like resource utilisation, billing details, etc. As we grew bigger, our users wanted to have multiple conditional notifications to manage this. Tanmoy then did Notification channel refactoring to address this. Now, customers can add multiple email addresses for each notification category, configure one customer mobile number to receive a call in case of confirmed incidents, and set up more specific notification channels at the team, site, and server levels.
Targeted dashboard banners
On similar lines, Jayanta launched Targeted dashboard banners allowing Frappe Cloud to communicate with specific cohorts at the team, site, or server level. Notably, what started as a downtime tool has also opened up a better way to announce changes and guide users contextually.

Growing up as a business platform
Signup flow refactor
One characteristic of Frappe is that we believe in organic product-led growth. Frappe Cloud signups are naturally critical for our growth. It affects all products alike. Repeated failures, slower end-to-end signup completion, and higher abandonment were common knowledge. People dropping off before they even got to experience the product was criminal. Over the year, Suhail and Bowrna took up the mantle of fixing this. They undertook refactoring of the signup flow with a focus on speed and reliability, and also removed smaller but frequent bugs. Since then, our signup metrics are looking up. (Honest confession - It is still not flawless, but it's getting better.)


Billing improvements
As the Frappe Cloud revenue grew, the Billing side required improvements. Aysha worked on some of these projects. She added PayPal as a payment option for USD customers. She also launched a month-end billing forecast on the dashboard (based on current usage and active subscriptions). She also added budget alerts for users to set thresholds and get notified when usage crossed a defined limit. Overall, we made material progress in the direction of making the Frappe Cloud billing experience more predictable, accessible and manageable.

New PRM
One of the more strategic shifts this year was moving partner operations from a scattered set of systems into Frappe Cloud itself. Internally, we fondly call this project - the “New PRM”. Shadrak from the operations team migrated most of these flows from frappe.io to cloud.frappe.io. The new PRM now has everything in one place. Partners can manage leads end-to-end from the dashboard, log follow-ups and activities, link certifications (including paid ones via Frappe School), renew partnerships with fewer manual steps, access all marketing and sales enablement collaterals, and keep their listing information up to date - all from one place. There is some scope for further refinement and stability, but that’s just a matter of time and diligence! (Read more)

Becoming more efficient and quality-focused
While most of the team’s time went on user-facing developments, there were some internal process fixes, quality measures and compliance we spent time and energy on as a group.
Agent update tool
As you may know, Press works through agents installed on servers. From time to time, we need to push changes to the agent for fixes and features. We used to do this via an “Update Agent” feature in Press. While this method worked, the process lacked flexibility; Frappe Cloud error logs would be flooded with timeout messages during updates, and there was no rollback capability. Tanmoy then developed a new Agent Update Tool to introduce controlled rollouts, automatic rollback, component-level restarts, and safer sequencing, significantly reducing the blast radius of mistakes. (Read more)
Playwright-based dashboard tests
Over time, even the dashboard grew in complexity. Backend tests alone were no longer enough to ensure they worked correctly with every update. Jayanta thus created Playwright-based dashboard tests to ensure reliable UI regression coverage, giving us far more confidence that everyday workflows continue to work as expected as the platform evolves.
Compliances & certifications
Business software is a game of trust! Compliances are thus central to our operations. In 2025, we completed our ISO 27001 recertification, got SOC 2 Type II certification, and also started regular VAPT exercises. This charter is owned by Sabu, Shadrak and Pushkar - our go-to compliance experts. (Know more)


Growth across all dimensions
All of the good work done by the Frappe Cloud team, applications teams and business team ultimately shows progress on one dimension - Scale. In 2025, we added 2 new clusters (Sydney, Johannesburg) to our network, taking the total to 13 globally. The number of servers went from around 300 to over 600, and the number of sites went from just over 10,000 to over 21,000 at the same time last year (i.e. ~2X growth in both metrics). Frappe Cloud revenue (which is Frappe’s primary revenue engine) grew from an MRR of ~$250k to ~$390k, i.e. a whopping ~55% growth. Frappe Cloud now contributes ~88% of Frappe’s monthly revenue, up from ~68% at the end of 2024.
During 2025, we added another dimension to our growth - Team. At the start of the year, the Frappe Cloud team was small and stretched thin (5 engineers, led by Aditya). Today, we have 15 members dedicated to Frappe Cloud, allowing us to move from constant firefighting to clear ownership. We now have people focusing specifically on performance, user experience, security, billing, support, and product marketing.

To multiply our internal bandwidth, we have been joined by BWH and rtCamp as contributors to manage the Frappe Cloud Marketplace. They have formed a working group (after a candid community discussion in Frappeverse 2025) to make the Marketplace better.
Looking back at 2025 and ahead at 2026
During 2025, we ticked quite a few boxes. First, we launched some critical features like Autoscaling, Database analyzer, Server storage breakdowns, etc. The team came together well to handle performance issues and made some proactive fixes that came frequently in support tickets. The engineering team seems to be in place now. The business team’s focus and conviction on Frappe Cloud has sharpened (which is also reflected in their regular up-skilling efforts).
However, not everything has gone as planned. The Bare-metal project is one example. Aditya had started this last year and was planning to make significant progress in 2025. The rationale was sound - better cost control and deeper ownership. We went through a couple of iterations, but we didn’t push it far enough amid competing priorities. There’s one more thing we’d admit honestly - we could have shipped faster (in some areas).
The direction for 2026 is clearer than it was a year ago. We want to properly launch bare-metal. We also want to invest more in developer tooling, both internal systems that help us move faster and external tools that make life easier for customers and partners. We will move towards offering services closer to Managed Databases and a broader Container Plane. On the compliance side, SOC 1 Type II is on the roadmap, building on the groundwork laid this year. We will expand into more regions as demand dictates, and will also launch options on cloud providers other than AWS and OCI (primarily for more economic hosting). As always, the goal isn’t to do everything. It’s to do fewer things well, and do them well!
Hope this recap was able to give you a comprehensive understanding of where Frappe Cloud is today and where it is headed next. Hope 2026 turns out to be a blockbuster for Frappe Cloud and for you as well!
Signing off from 2025!
Frappe Cloud team


·
Great Job guys... keep up the great work :-)