

In Frappe Framework, everything revolves around documents - listing, reading, creating, updating, reviewing, submitting, and deleting documents. This is how a typical list view looks like, each row represents one document and you can configure the most important fields to show up on list view.

The list view is such an important view that it used to be responsible for ~20% of CPU time (wall) we spend on Frappe Cloud. We have refactored this view many times, and it also undergoes constant incremental improvements in terms of UX, correctness, and performance. To understand just how complex a list view can be, let's just look at one small part of it - document counts.
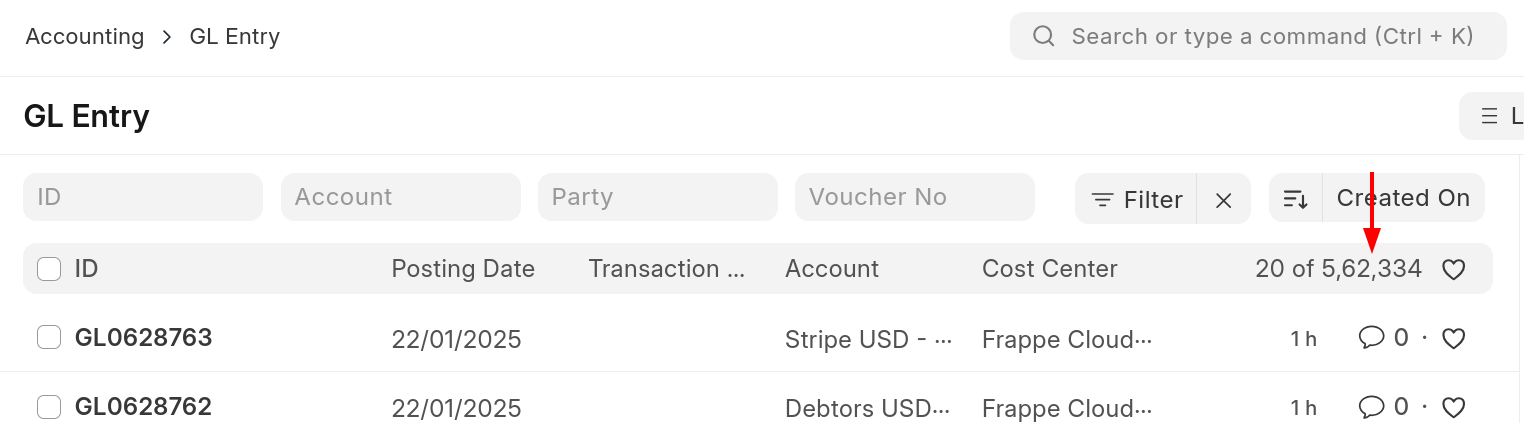
This count was first introduced in a list view refactor back in 2017. The purpose of this change and the PR was to improve code quality and user experience. Showing the total count of all documents might not seem that helpful, but in our implementation, the count also reflects the selected filters.
Users can very quickly get an idea about how many documents exist matching a particular filter. E.g. How many orders I've received from this customer? While we have full blown reporting and business intelligence tools available too, this small feature avoids the mental overhead of reaching for those heavy weight tools.
First signs of trouble
A couple of years go by, this feature is now part of stable versions. We received a request for request POC from a user with millions of records. Very quickly we realized that this list view design where we show accurate count of all matching records is not feasible on such large databases. To make matters worse, we automatically refresh this list view when documents are updated or new documents are created.
select count(*) where ... when no index can be used is an O(N) operation which essentially gets converted to a for-loop iterating over all rows in the table:
def count_query(table, filters):
count = 0
for row in table:
if evaluate_filters(row, filters):
count += 1
return count
 When it comes to counting, databases are like Count von Count.
When it comes to counting, databases are like Count von Count.
Image credit: Fandom
This often feels fast enough on large tables when you're not filtering for anything specific or you're filtering using some indexed columns. When the filters are applied on columns without an index this becomes an excruciatingly slow process. It's not unheard of to see these count queries take >2 minutes and we terminate any request that takes more than 2 minutes.
Even if you drop the filters, some databases do not keep an accurate count of records, so it's still an O(n) operation, albeit with a smaller constant factor.
We provided an escape hatch to users with large tables, they can now disable counts and automatic refreshes on the list view. So they never have to worry about the performance impact of counting, but they also can't get the UX benefit now.
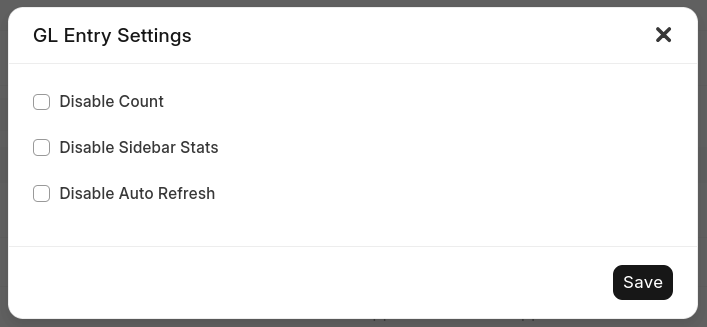
Incremental optimizations
Document count is explicitly added for UX, so we can't let it cause an unacceptable amount of degradation in performance. We identified and optimized a few things over time.
The first major task was to reduce the excess load created by automatically refreshing the list view. Instead of updating in real-time we now started throttling it. This controlled our self-inflicted DDOS when multiple users were updating documents all at the same time. Beyond this major change, we also made several micro-optimizations to reduce the number of accesses to the database and cache. All of them only lessen the impact of the problem - in the worst case the query can still take 2 entire minutes and the only thing a user can do is to disable it.
A different approach
One important realization we had was - users don't care about accurate counts beyond a certain number. Take the same old example of "I want to see how many orders this customer has created". In MOST cases, that number is going to be somewhere between 0 and 100. So we decided to limit the count to 1000 by default.
How does this help? We can now make the database stop counting as soon as 1000 records are found, this drastically reduces the amount of data that needs to be accessed. The modification is just a small rewrite of the original query.
-- before
select count(*) from table where ...;
-- after: Original query is now a subquery
select count(*) from (select name from table where ... limit 1001) temp;

We still provided an escape hatch where users can click on the limited count to fetch accurate and complete counts. This is rarely required in practice.
Not good enough
Few months go by and this count endpoint was still in top 5 requests by wall clock time. It went down from its original position but it was not not enough. We still had performance issues where only solution was to recommend disabling this feature. Even if we limit the query to first 1000 rows, there can still be filters that do not even yield 1000 matching rows. In such cases, database will end up scanning entire table, just like before. E.g. there are no unpaid invoices and status is not indexed.
-- this will read the entire table and return 0
select count(*) from invoice where status = 'unpaid'
I applied a few more micro-optimizations like caching the capped count using HTTP caching, but that too didn't solve the main problem: This query has unbounded running time. It can take anywhere from a few milliseconds to up to 2 minutes until the request is timed out.
We know that this feature only exists for the sake of improving UX, so under no circumstances it should degrade it. Thus using statement timeouts, we added a hard limit of 1 second for fetching count results. If that query times out i.e. exceeds 1 second, we simply do not show the count. The final query now looks like this:
SET STATEMENT max_statement_time=1 FOR
select count(*) from (select name from table where ... limit 1001) temp;
Users can still explicitly request it if they want to. In the current state, I can confidently say that we have made the "Disable Count" configuration unnecessary for almost all of our users.
Conclusion
Few takeaways from these iterations:
select count(*)has a bad reputation and for a good reason, but it's still worth preserving it for user experience.- A global request timeout is not good enough, don't be afraid to tweak it for specific frequent requests.
- Frequent requests need to have a reasonably bounded runtime by design.
- Escape hatches are an important short-term intervention, but that is still a manual intervention. Things should just work.


·
We have benefited using count(name) in many cases (when CBO is in use) irrespective of what the where clause is eg: select count(name) from
tabSales Invoicewhere status = 'Unpaid' would run faster instead of count(*) so this should be a change across the application enforced maybe via query builder.We have seen slowness in pulling older fiscal year(s) data because of caching at DB Level (Eg: Current year is 2025 but the user is trying to pull an Invoice from 2018 for some reason etc. This many times is the culprit where we see slowness in Frappe.
·
@Matt that kind of counter only helps with the total count. We also support count with arbitrary filters (that become part of WHERE clause in count query).
·
Interesting post :) assuming every row is one order I’d, have you tried adding a row number over the partition of customer id or name? Then you could use max() to find the largest row number per customer.
·
Great insights, Ankush! Facing similar challenges with count queries; nice perspective on optimizing them!